
Most organizations treat AI as a standalone purchase rather than a component of their operating system. This approach wastes resources and creates friction across teams.
At Ailudus, we’ve observed that companies building an AI business instrument framework-one aligned with existing processes and governance-generate measurable returns while avoiding costly implementation failures. Structure comes first. Technology follows.
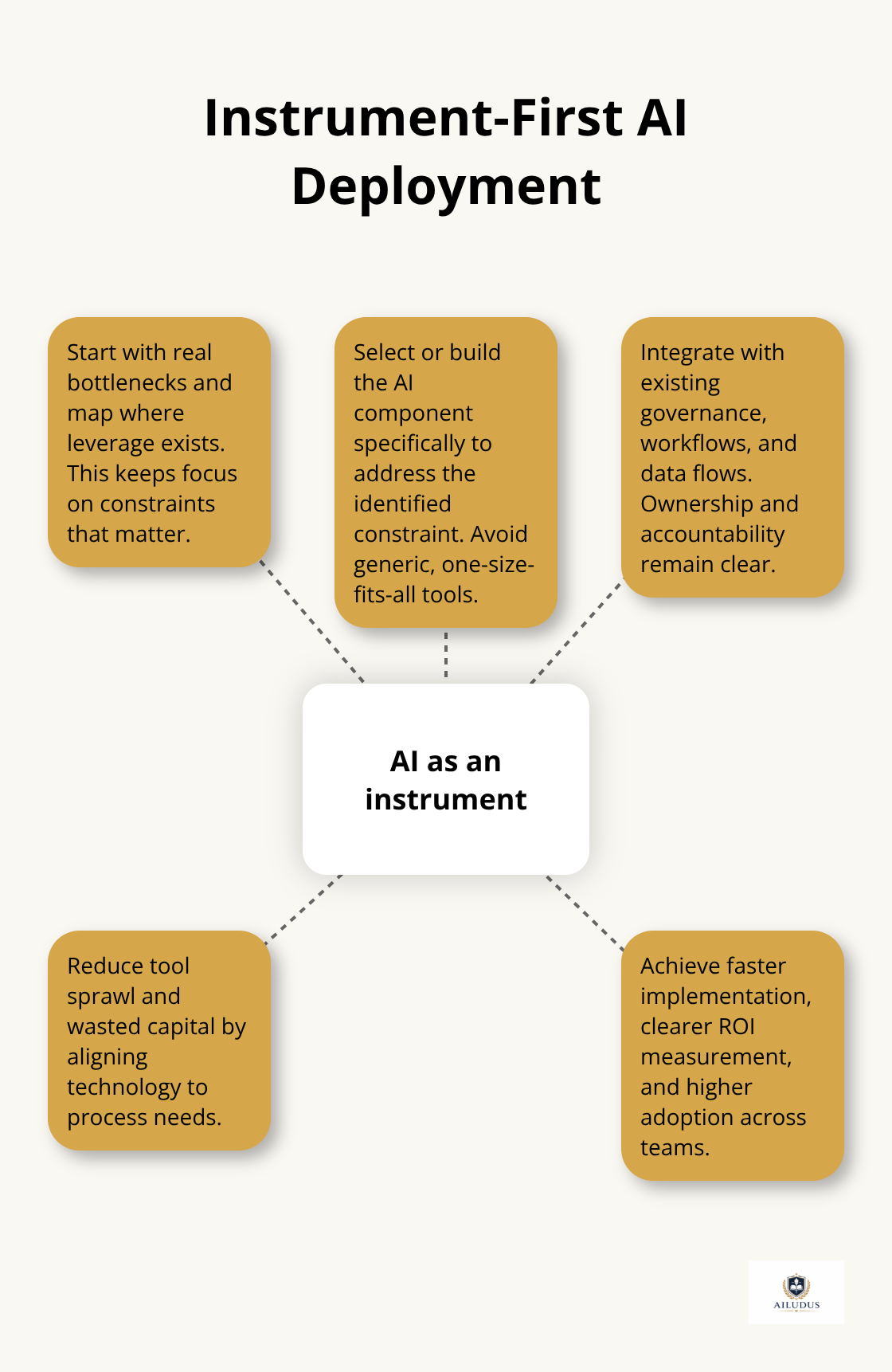
Structure Shapes How Your Operating System Works
Your operating system is already built. It has workflows, decision-making hierarchies, data flows, and accountability structures whether you’ve documented them or not. AI inserted into this system without understanding it creates friction, redundant tooling, and wasted capital. The opposite approach-retrofitting your operations around a new AI tool-is worse. It destabilizes what works and subordinates your business logic to whatever the vendor optimized for.
The Cost of Reversing Your Sequence
Most organizations acquire an AI capability first, then search for problems it might solve. This inversion produces tool sprawl. According to IoT Analytics research tracking 530 generative AI projects from 2022 to 2024, organizations that succeeded treated AI as an instrument within an existing operating system. They started with bottlenecks, mapped where genuine leverage existed, and then selected or built the AI component to address that specific constraint. Organizations that started with the tool-treating it as a standalone solution-either abandoned it or maintained it as an expensive experiment disconnected from core workflows.
The difference in execution cost and actual return is substantial.
Companies that align AI deployment with their existing processes report faster implementation, clearer ROI measurement, and higher adoption across teams because the tool amplifies what already works rather than forcing teams to reorganize around the tool.
Why Tool-First Thinking Fails
Tool-first approaches fail because they ignore governance and ownership. When an AI capability arrives without a defined decision protocol-who uses it, when, for what outcomes, and who is accountable if it fails-adoption stalls or creates shadow systems. Teams build workarounds. Multiple departments purchase competing tools. Your infrastructure becomes fragmented, and data silos prevent the very AI systems from functioning effectively.
Klarna’s customer service agent handled the workload of 700 agents across 23 markets in 2024 because it was embedded within Klarna’s existing customer support structure, not grafted on top of it. The governance layer already existed. Accountability was clear. The AI instrument enhanced a defined process rather than replacing it.
Map Bottlenecks Before You Select Tools
Start by mapping your core business processes and identifying where friction actually exists. Not where you think AI might be interesting, but where bottlenecks create measurable cost or delay. Customer support issue resolution represents a significant portion of generative AI projects because organizations could measure the bottleneck-response time, ticket volume, coverage gaps-and could directly attribute improvement to the AI deployment.
Once you’ve identified the constraint, evaluate whether AI addresses it or whether the constraint is structural and requires process redesign first. Then design the governance protocol around that specific workflow. Who initiates the AI decision? What data feeds it? Who validates the output? What happens if the output is wrong? This governance layer must integrate with your existing accountability structure, not create a parallel one.
The next step requires you to move from diagnosis to design-building the actual framework that connects your bottlenecks to the AI instruments that will address them.
How to Diagnose Your Bottlenecks and Build Your Framework
The framework begins with diagnosis, not aspiration. You need to map your actual workflows, identify where friction consumes time or capital, and measure the friction in concrete terms. Most organizations skip this step because it requires disciplined observation rather than vendor conversations. Start by documenting your three to five core business processes-the workflows that generate revenue or directly support revenue generation. For a customer support operation, this might be ticket intake, classification, response, and resolution. For a product team, it might be design iteration, code review, testing, and deployment. For a sales operation, it might be lead qualification, proposal generation, negotiation, and close. Write these down. Map the actual steps, the people involved, the tools used, and the decision points. This is not theoretical. Walk through one complete cycle of each process and time it. Identify where delays occur and what causes them.
Start with Measurement, Not Assumptions
According to IoT Analytics research on 530 generative AI projects deployed between 2022 and 2024, organizations that succeeded started with diagnostic work. They measured response times in customer support before deploying AI. They tracked code review cycles before implementing copilots. They documented proposal generation time before automating content creation.

Measurement creates the baseline. Without it, you cannot attribute improvement to the AI instrument or justify continued investment. This baseline transforms vague complaints about speed into actionable constraints that you can address with precision.
Separate Bottlenecks from Broken Processes
Not every bottleneck should be solved with AI. Some constraints are structural and require process redesign first. If your customer support bottleneck stems from unclear escalation protocols or poor data organization, an AI system will amplify the dysfunction rather than resolve it. If your sales bottleneck is poor lead quality, not proposal drafting speed, automating proposal generation wastes resources. This distinction matters because organizations often deploy AI to compensate for broken processes, creating expensive technical solutions to organizational problems.
Covered California used generative AI to automate document verification and raised accuracy from 28–30 percent to 84 percent, but this only worked because the underlying process-document classification-was clearly defined and the bottleneck was genuinely about speed and consistency, not about process logic. Before you select an AI instrument, confirm that the execution-based bottleneck is genuine.
Define Governance Around the AI Decision
Once you’ve isolated genuine execution bottlenecks, define the governance protocol around the AI decision. Who initiates the AI process? What data must feed the system for it to function? Who validates the output before it moves downstream? What happens if validation fails? What metrics indicate the system is performing as intended? This governance layer must connect to your existing accountability structure. Assign clear ownership. Make the AI instrument accountable to the same metrics and reviews as the rest of the operation. This prevents shadow systems and ensures the AI component behaves as an instrument serving your operating system rather than as an isolated experiment.
The governance protocol transforms AI from a disconnected capability into a managed component of your workflow. With this structure in place, you move from framework design into the practical work of execution-establishing ownership across teams and building the feedback mechanisms that keep your AI instruments aligned with your business outcomes.
Execution Requires Clear Ownership and Systematic Feedback
Assign explicit ownership to each AI instrument
Governance on paper means nothing without someone accountable for enforcing it. Assign explicit ownership of each AI instrument to a specific person or role, not a committee. This owner defines how the tool integrates with the workflow, monitors its performance against the metrics you established during diagnosis, and makes decisions about adjustment or escalation when performance drifts. At Klarna, someone owned the customer service AI agent’s performance against response time and accuracy targets across 23 markets. Without that ownership, the system would have fragmented into regional variations, inconsistent standards, and competing interpretations of how it should function.
The owner is not the person who uses the tool daily. They are the person accountable for whether it delivers the intended outcome. They review performance weekly or monthly depending on deployment velocity, adjust parameters or training data when metrics decline, and escalate when the system encounters cases it cannot handle reliably. This is operational discipline, not overhead.
Monitor Performance and Adjust Parameters
Organizations that skip explicit ownership treat AI instruments as set-and-forget deployments and discover months later that adoption has stalled, performance has degraded, or the tool has drifted into uses it was never designed for. The owner reviews performance data against your baseline metrics, identifies when the system underperforms, and initiates retraining or recalibration before drift becomes severe. This prevents the slow decay that renders AI instruments irrelevant to actual workflows.
Build feedback loops into your workflow
Feedback loops must be built into the workflow itself, not added afterward as an afterthought. When the customer support agent generates a response, the human agent reviewing it flags accuracy issues and retraining signals flow back into the model. When the code copilot suggests a function, the developer accepts or rejects it, creating performance data about suggestion quality in actual contexts. Product teams, behavioral and AI scientists, and operation specialists should collaborate to monitor performance and gather user feedback continuously.
Without this closed loop, your AI instruments become static, performance plateaus, and the tool gradually becomes less relevant to actual workflows. Establish who captures feedback, how frequently they review it, and what threshold of performance decline triggers retraining or recalibration. Make this a standing operational task assigned to the owner you identified, not an occasional audit.
Scale incrementally across workflows
Scale your AI instruments incrementally across workflows only after you’ve demonstrated stable performance and clear ROI in the initial deployment. Expanding too quickly creates technical debt-undocumented configurations, inconsistent governance across teams, and fragmented data pipelines that become expensive to untangle later. Start with one core process, run it for three months, measure the results against your baseline, and only then expand to adjacent workflows.
This disciplined approach prevents the tool sprawl that undermines long-term leverage. Each expansion follows the same governance and feedback protocol as the initial deployment, applied to the new workflow’s specific constraints. The owner remains accountable for performance across all deployments, ensuring consistency and preventing the fragmentation that undermines sustainable operations.
Final Thoughts
Organizations that generate measurable returns from AI treat it as an instrument within a disciplined operating system, not as a standalone purchase. Your structure determines how effectively any technology functions within it. Weak governance, unclear ownership, and fragmented processes undermine even sophisticated AI deployments, while strong structure amplifies the leverage that AI provides. The AI business instrument framework reverses the sequence most organizations follow by starting with bottlenecks rather than vendor pitches, mapping friction in concrete terms, and designing governance that integrates AI into your existing accountability structure.
Klarna scaled a customer service agent across 23 markets because it assigned explicit ownership, built feedback loops into the workflow, and measured performance against baseline metrics. Covered California raised document verification accuracy from 28 percent to 84 percent through the same disciplined approach. This work requires observation, documentation, and operational discipline rather than innovation theater, yet it produces results that compound over time because your AI instruments remain aligned with actual workflows and improve through systematic feedback.

Long-term leverage comes from treating technology as a managed component of your operating system, governed by the same standards of accountability that apply to the rest of your business. We at Ailudus publish frameworks and playbooks designed for builders navigating the AI age, focusing on turning skill into leverage through structure rather than shortcuts.
— Published by Ailudus, the operating system for modern builders.