
Most builders treat their AI stack as a collection of point solutions. They bolt tools together without considering how components interact, fail, or scale.
At Ailudus, we’ve seen this pattern repeatedly: teams spend months optimizing individual pieces while their entire system remains fragile. The real work isn’t selecting the best model or API-it’s architecting a toolchain that survives contact with production.
This post covers the structural decisions that separate resilient systems from brittle ones.
Structural Decisions That Matter
A resilient AI stack rests on three structural choices that most builders overlook: how you separate concerns across components, how data flows between them, and what happens when something breaks. These aren’t abstract principles-they determine whether your system survives the first production incident or collapses under load.
Each Component Owns One Job
Separation of concerns means each component owns one job and executes it well. A feature store shouldn’t also handle model serving. Your orchestration layer shouldn’t embed business logic. When components have fuzzy boundaries, failures cascade unpredictably and debugging becomes forensic archaeology.
Start by mapping what each tool actually does: data ingestion, transformation, training, inference, monitoring. If any tool claims to handle three of these equally well, it probably handles none of them excellently. The Neptune MLOps survey found that 90+ specialized tools exist across categories like experiment tracking, data labeling, and model deployment precisely because integrated solutions create bottlenecks. Your job is selecting the right specialist for each function, not finding one platform that does everything mediocrely.

This means accepting that your stack will have multiple vendors. That’s not a weakness-it’s a sign you’ve made intentional choices about what each component must deliver.
Data Movement Requires Explicit Patterns
Data flowing through your stack must follow predictable paths with clear ownership. Too many builders treat data movement as a side effect rather than a core architectural concern. When raw data arrives, where does it land first? Who validates it? Where does it move next? These questions must have explicit answers.
Data lineage in AI systems allows you to quickly pinpoint the root cause when issues arise in your data pipelines. You trace whether the problem originated in data quality, feature transformation, or model logic. Without lineage, you’re guessing.
Tools like DVC, Dolt, and LakeFS provide version control for datasets, tying specific training runs to specific data snapshots. This reproducibility matters more than most builders realize. When a model trained last month suddenly performs poorly, you need to know whether the underlying data distribution shifted or whether a transformation rule changed. Real infrastructure includes this tracing from day one, not as an afterthought.
Failure Modes Require Design
Every component in your stack will fail. The question is whether failure in one component brings down the entire system or whether you’ve designed boundaries that contain the damage. This is where redundancy and explicit failure handling enter.
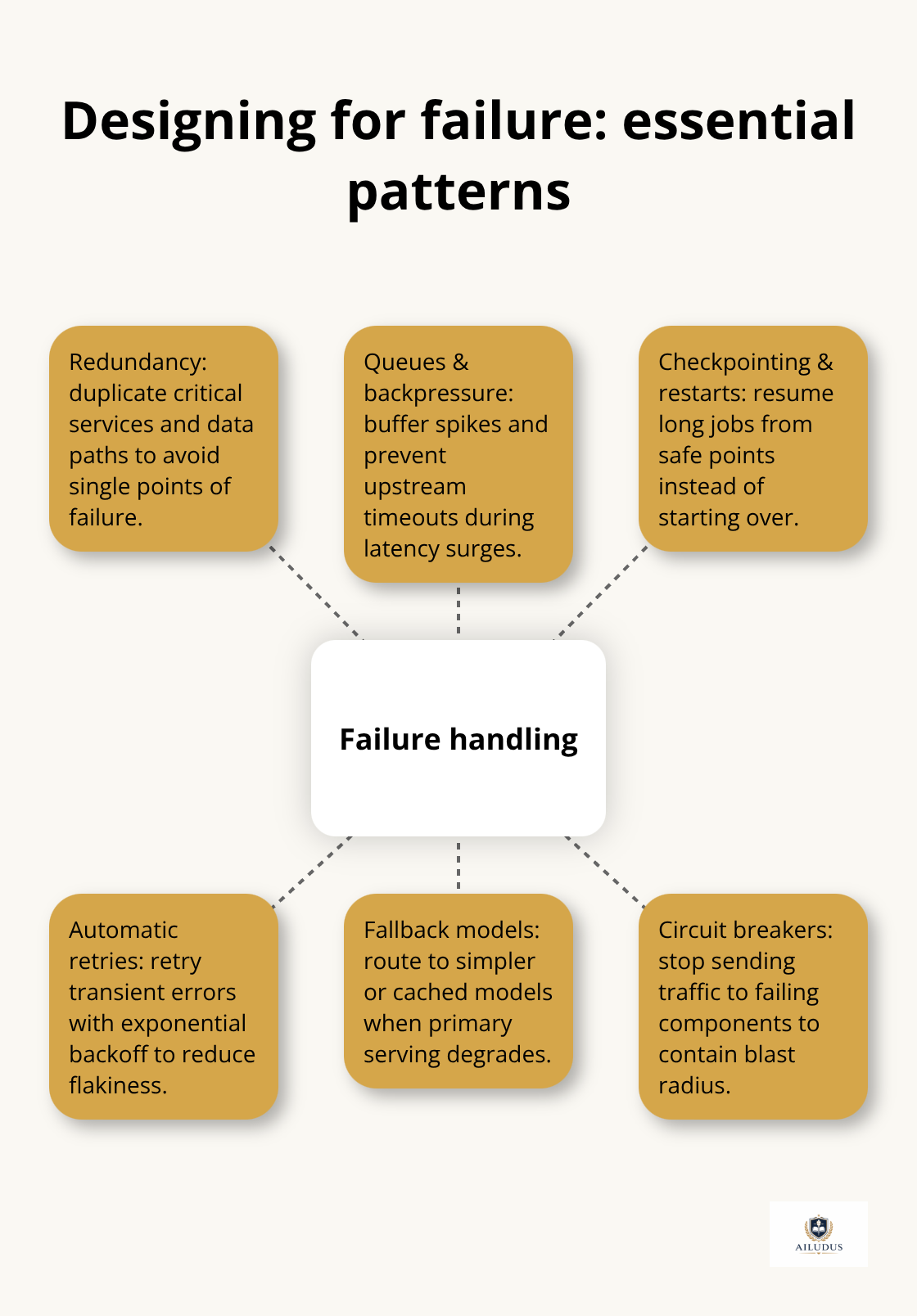
If your feature store goes down, can inference still run using cached features? If your model serving layer experiences a spike in latency, do requests queue gracefully or do they timeout and cascade failures upstream? These aren’t edge cases-they’re predictable scenarios that happen in production regularly. Failure handling in production ML systems requires adding redundancy throughout critical flows at different workload layers to optimize resiliency.
If model serving matters for your business, you need at least two serving instances behind a load balancer. If a training pipeline is critical, you need checkpointing and restart logic so a failure at hour 23 of a 24-hour run doesn’t force you to start over. The MLOps toolchain approach from platforms like Databricks and Vertex AI includes built-in recovery mechanisms: automatic retries, fallback models, and circuit breakers that stop routing requests to failing components. You can implement similar patterns with open-source orchestration tools like Flyte or Prefect, which handle dependency management and provide observability into which steps succeeded or failed.
Observability Connects Structure to Action
The cost of not building failure handling into your architecture is measured in production incidents, not in engineering hours. But you can’t respond to failures you don’t see. Observability-the ability to understand system state from external outputs-transforms your stack from a black box into something you can actually operate.
Observability differs from monitoring. Monitoring tells you that latency increased. Observability tells you why: whether the problem lives in data quality, model inference time, or downstream API calls. Tools like Arize AI, WhyLabs, and Evidently AI track model drift, data drift, and performance degradation across production workloads. They connect your data lineage to your model outputs, so when accuracy drops, you can trace the root cause rather than restart everything and hope.
This foundation-separation of concerns, explicit data patterns, designed failure modes, and observability-creates the conditions where your next architectural decision becomes possible: selecting components that actually work together rather than components that merely coexist.
Matching Components to What Actually Matters
Start with Constraints, Not Tools
Selecting components for your AI stack starts with a brutal inventory: what does your system need to do, and what are the constraints under which it must do it? Most teams skip this step and instead chase what other builders use or what vendors market aggressively. This produces stacks optimized for someone else’s problem.
Successful deployments share one pattern: they map functional and performance requirements first, then select tools that address those specific requirements. If your bottleneck is data labeling speed, investing in experiment tracking won’t help. If your constraint is inference latency, a sophisticated feature store won’t solve it.
Name what actually constrains your business: Is it training time? Inference cost? Model accuracy? Data freshness? Once you identify the real constraint, you can evaluate whether a tool meaningfully addresses it. Most builders waste engineering effort optimizing non-constraints.
Feature Stores and Consistency
A feature store like Feast, Tecton, or Hopsworks makes sense only if consistency between training and serving costs you production incidents or model degradation. If your models train infrequently and your data changes slowly, a feature store adds operational overhead without delivering value.
Conversely, if you serve personalized models to thousands of users in real time, a feature store becomes non-negotiable. It guarantees that training features and serving features remain synchronized. The same logic applies to experiment tracking, model registries, and orchestration platforms. Each tool exists to solve a specific class of problem. Your job is matching problems to solutions, not collecting tools.
Design Failure Modes and Recovery
When a component fails, does the entire stack halt or does it degrade gracefully? Production systems require robust error handling and retries-automatic retries with backoff, fallback strategies, and circuit breakers-to prevent cascading failures. If you use open-source tools like Flyte or Prefect for orchestration, you need to explicitly configure checkpointing and restart policies so that a failed training step doesn’t force you to restart from scratch.
Similarly, if your inference layer serves requests to users, you need caching or fallback models so that a serving instance failure doesn’t immediately degrade user experience. This isn’t optional complexity-it’s the difference between a production incident lasting minutes versus hours.
Version Everything
Version control for your entire stack, including data pipelines and model artifacts, prevents the scenario where you can’t reproduce what was working last week. Tools like DVC provide dataset versioning alongside code versioning, so you know exactly which data snapshot trained which model. Without this, troubleshooting becomes guesswork.
Connect Production Signals to Development
Establish explicit feedback loops between production performance and your development process. Arize AI and WhyLabs surface data drift and model performance degradation automatically, alerting you to problems before they become severe. Without observability wired into your toolchain, you respond to customer complaints rather than proactive signals from your own infrastructure.
These decisions-matching constraints to tools, designing recovery patterns, versioning everything, and wiring observability into your stack-create the foundation for the next critical choice: how you actually build and operate the system over time.
Common Pitfalls in AI Stack Design
Over-Engineering Solves Tomorrow’s Problems Today
The most dangerous moment in AI stack design arrives when you have enough success to feel confident but not enough operational maturity to handle what you’ve built. This is when teams add layers of abstraction, integrate tools that promise to unify everything, or design systems so elaborate that only the original architect understands them. The result: a stack that works until it doesn’t, and when it breaks, nobody can fix it quickly.
Over-engineering manifests as selecting platforms that solve problems you don’t have yet. A team with one model and straightforward batch inference doesn’t need a feature store, model registry, and experiment tracking orchestrated across Kubernetes. Yet teams implement exactly this because they read case studies from companies operating at scale. The cost is real: every additional component increases operational surface area, requires monitoring, demands expertise, and introduces new failure modes.
Databricks and Vertex AI are powerful platforms, but they’re overkill for teams still figuring out whether their model actually solves a business problem. Start with the minimum viable stack that addresses your actual constraint. Add complexity only when you’ve hit the limits of your current setup and can articulate precisely what problem the new component solves. This discipline prevents the scenario where your team spends 40 percent of engineering effort maintaining infrastructure instead of improving models or data quality.

Vendor lock-in Accumulates Silently
Vendor lock-in happens gradually, then suddenly. You select a cloud provider’s managed services because they integrate seamlessly, then build your data pipelines, model training, and serving around those integrations. Eighteen months later, switching costs are astronomical. The practical defense is straightforward: standardize on open formats and protocols.
Use JSON-LD for data exchange between components instead of proprietary schemas. Choose orchestration tools like Flyte or Prefect that don’t require you to commit to a specific cloud. If you use a feature store, Feast works across clouds while vendor-specific options like Databricks Feature Store don’t. These choices seem minor during implementation but determine whether you can migrate infrastructure without rebuilding your entire stack.
Operational Overhead Multiplies Quietly
Operational overhead multiplies when you neglect upfront decisions about maintainability. Teams often discover too late that their chosen tools require constant tuning, frequent updates that break dependencies, or expertise that’s rare in the market. Before adopting any component, ask: who operates this in production? What’s the failure mode when it breaks? How often does it require maintenance?
If the answer is that it requires a specialist you can’t hire or constant babysitting, it’s the wrong tool regardless of its technical merits. The toolchain that survives long-term is the one your team can actually operate without burning out. Your infrastructure should amplify your team’s capacity, not consume it.
Final Thoughts
Resilient AI stack architectures rest on three non-negotiable decisions: separating concerns so components fail independently, making data movement explicit and traceable, and designing recovery patterns before production breaks them. These principles aren’t theoretical-they determine whether your system survives its first incident or collapses under cascading failures. The teams building durable systems start with constraints, not tools, and name what actually limits their business before selecting components that address those specific constraints.
Vendor lock-in accumulates silently through small integration choices that seem reasonable in isolation. Standardize on open formats, choose tools that work across cloud providers, and build your stack so you could migrate components without rebuilding everything. Over-engineering solves tomorrow’s problems today and consumes engineering capacity that should go toward improving models or data quality, while operational overhead multiplies quietly when you adopt tools that require constant tuning or expertise you can’t hire.
At Ailudus, we help builders construct operating systems that turn skill into leverage through disciplined structure. Our frameworks cover system design, ownership models, and practical execution using contemporary technologies. If you’re building an AI stack that needs to survive beyond the prototype phase, explore how intentional design transforms your infrastructure into a competitive advantage.
— Published by Ailudus, the operating system for modern builders.